Itrameur
Pour la première partie, on va analyser les segments répétés, qui nous permet d’obtenir une suite de formes dont la fréquence est supérieure ou égale à 2. Pour le français, le coréen et le chinois, nous avons d’abord regardé les segments répétés dans le fichier dump concaténé, mais le fichier étant segmenté, les segments les plus fréquents étaient des particules. Nous avons alors choisi d’analyser le fichier des contextes concaténés, qui donne des résultats un peu plus cohérents. Pour La deuxième partie, on va voir les cooccurrents, qui sont les mots se trouvant dans le contexte autour d’un mot.Dans cette partie-là, il est facile de voir que, contrairement à ce qui s'est passé auparavant, les fichier contexte n'ont pas beaucoup de sens par rapport aux fichiers dump. Du coup, on prend les fichier dump pour cette fois-ci.
Pour le coréen :
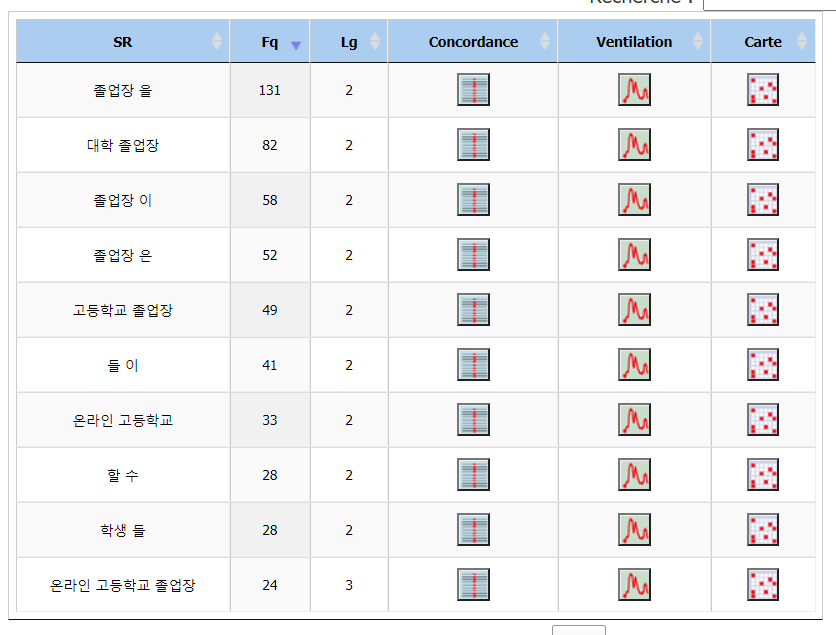
-les segments répétés :
Le mot 졸업장 (diplôme) apparaît plusieurs fois suivi de particules, mais on peut aussi voir apparaître les segments 대학 졸업장 (diplôme universitaire), 고등학교 졸업장 (diplôme de lycée), et 온라인 졸업장 (diplôme en ligne).
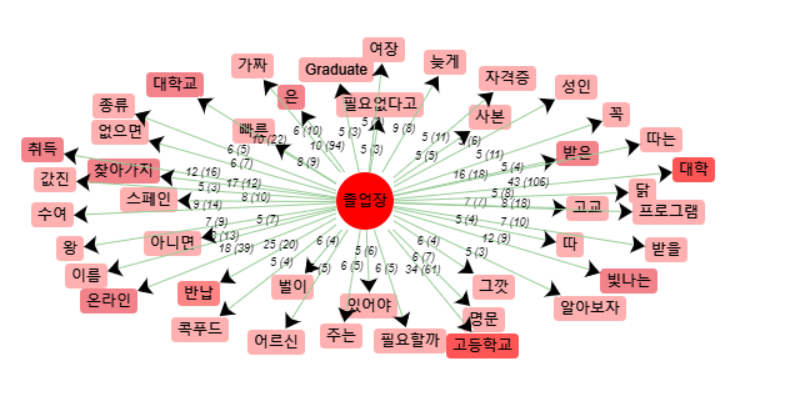
-les cooccurrents :
Pour cette analyse, nous avons choisi d’étudier un contexte comprenant les 10 mots autour du mot 졸업장 (diplôme). Parmi ces cooccurrents, on retrouve beaucoup de vocabulaire lié à la scolarité et aux diplômes, comme 대학 (universitaire), 고등학교 (lycée), 대학교 (université), 반납 (restitution), 받은 (obtenu), 취득 (obtention), et 자격증 (certificat), ainsi que quelques mots se rapportant à la qualité du diplôme et à l’avenir après son obtention, tels que 명문 (prestigieux) et 가치 (valeur), 빛나는 (brillant) et 벌이 (revenu). En plus de ces mots auxquels on pouvait s’attendre, on peut apercevoir un schéma se formant autour de mots moins attendus, tel que 늦게 (tard) et 어르신 (personne âgée), qui se rapportent à des articles parlant de personnes ayant obtenu leur diplôme à un âge avancé. On peut également entrevoir d’autres moyens d’obtenir son diplôme, avec 온라인 (en ligne), 스페인 (Espagne) et 미국 (Etats-Unis). En effet, le système scolaire actuel en Corée du Sud est très exigeant, et certaines personnes préfèrent étudier autrement, que ce soit à l’étranger ou en ligne. D’autres se demandent s’ils peuvent se permettre d’arrêter leurs études, comme on peut le voir avec les mots 필요할까 (a-t-on vraiment besoin), 없으면 (si je n’ai pas), 필요없다고 (ne pas avoir besoin) et 그만한 (arrêter). Enfin, la dernière solution de certains est la fraude. Les mots 가짜 (faux), 빠른 (rapide), 주는 (donner), 꼭 (absolument), et 사본 (copie) le montrent bien, la fabrication de faux diplômes est une réalité en Corée du Sud, car avoir un diplôme est quelque chose d’essentiel pour réussir sa vie d’un point de vue coréen.
Pour le français :
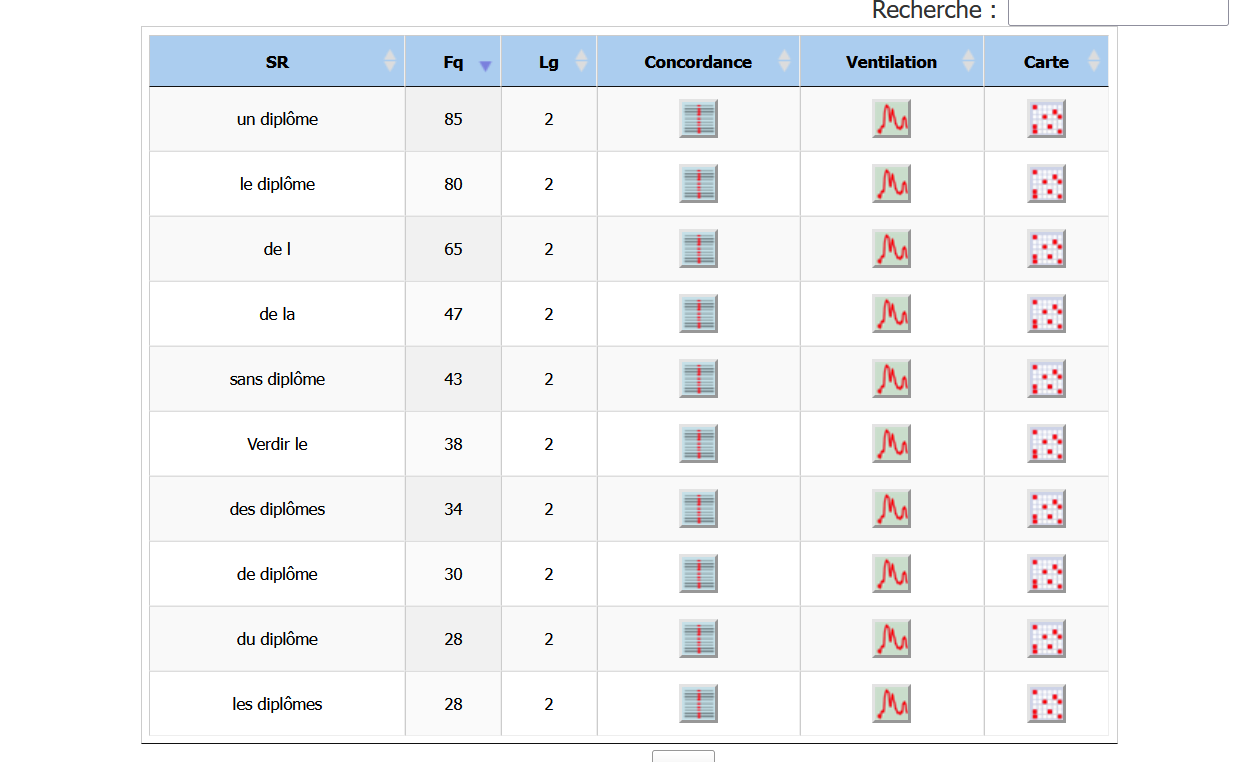
-les segments répétés :
En français, on a bien constaté que dans l’option segment répété, à part l'article partitif et l’expression plus accentués dans le texte spécial, tel que « de la » et « Verdir le ». Ce sont presque les articles ou adverbes qui précédent le mot « diplôme » qui correspond précisément à la structure grammaticale de la langue française, d'un point de vue syntaxique.
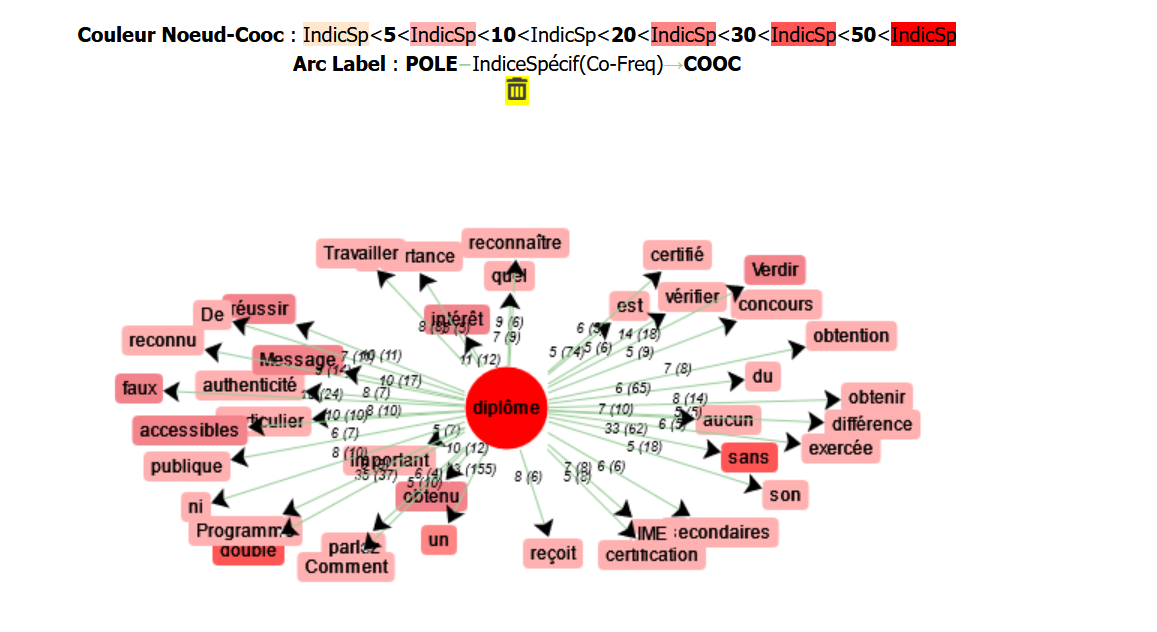
-les cooccurrents :
Ce diagramme de coconcurrence montre au premier vue que certains mots, comme « sans », « double », « obtenir », « réussir » sont non seulement plus fréquents, mais également liée d’une certaine manière façon au mot « diplôme ». Il s'agit en partie d'une réaction au fait que, dans les forums et les blogs, les principaux sujets abordés autour du mot « diplôme » touchent l'obtention d'un diplôme, l'absence de diplôme, la réussite, etc. De plus, à partir des mots « reconnu », « reconnaître », « authenticité», il est facile d'analyser que l'acceptation des diplômes est également un sujet relativement discuté sur Internet. Un autre sous-thème connexe doit être mentionné ici. En effet, lorsque on se penche sur ces mots, on se demande pourquoi l'acceptation des diplômes est un sujet aussi controversé. On observe que ce mot « faux » apparaît aussi fréquemment dans des articles où l'on parle de la façon de fabriquer ses propres diplômes, d'avoir un faux diplôme et de savoir si ces diplômes seront acceptés.
Pour le chinois :
-les segments répétés :
Ici on peut voir que les mots 学位证书 xuéwèi zhèngshū et 毕业证书 bìyè zhèngshū apparaissent dès la première page de résultat, puisqu'il s'agit de mots composés (suite de 2 mots formes qui forme un mot) et on ne s'étonne pas de ne pas voir 文凭 wénpíng qui est un mot dont la forme est isolée dans son emploi.
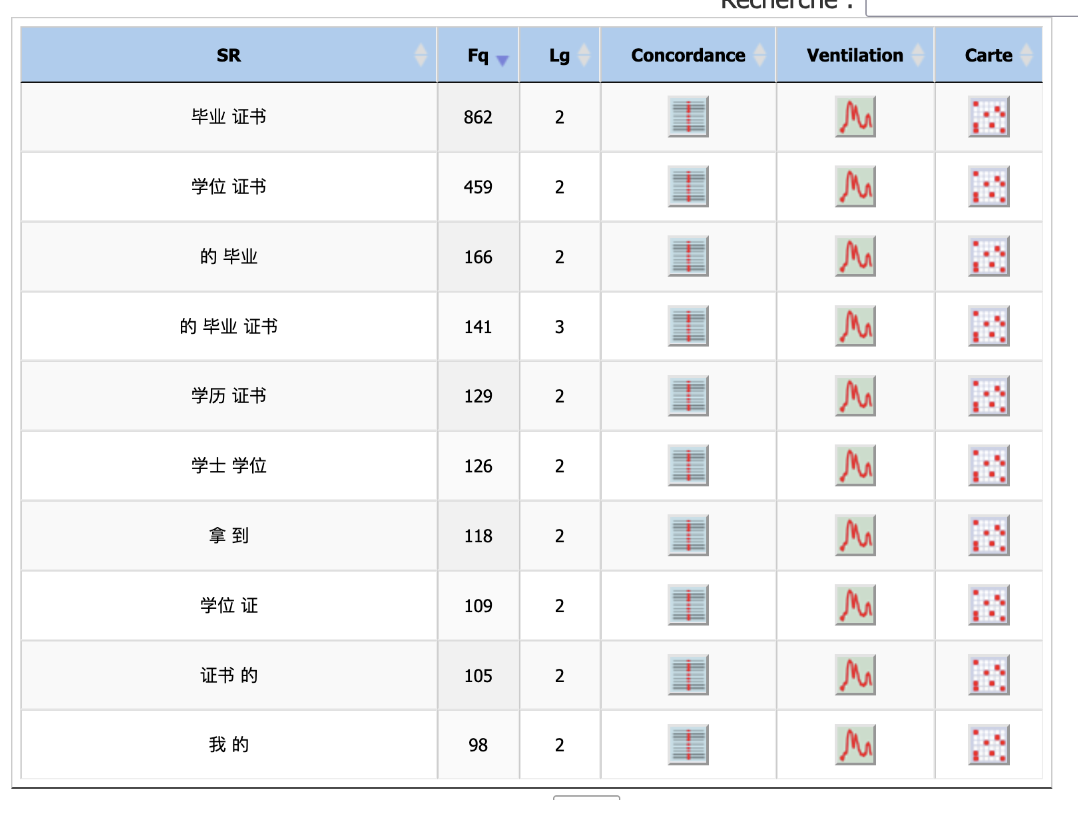
-les cooccurrents :
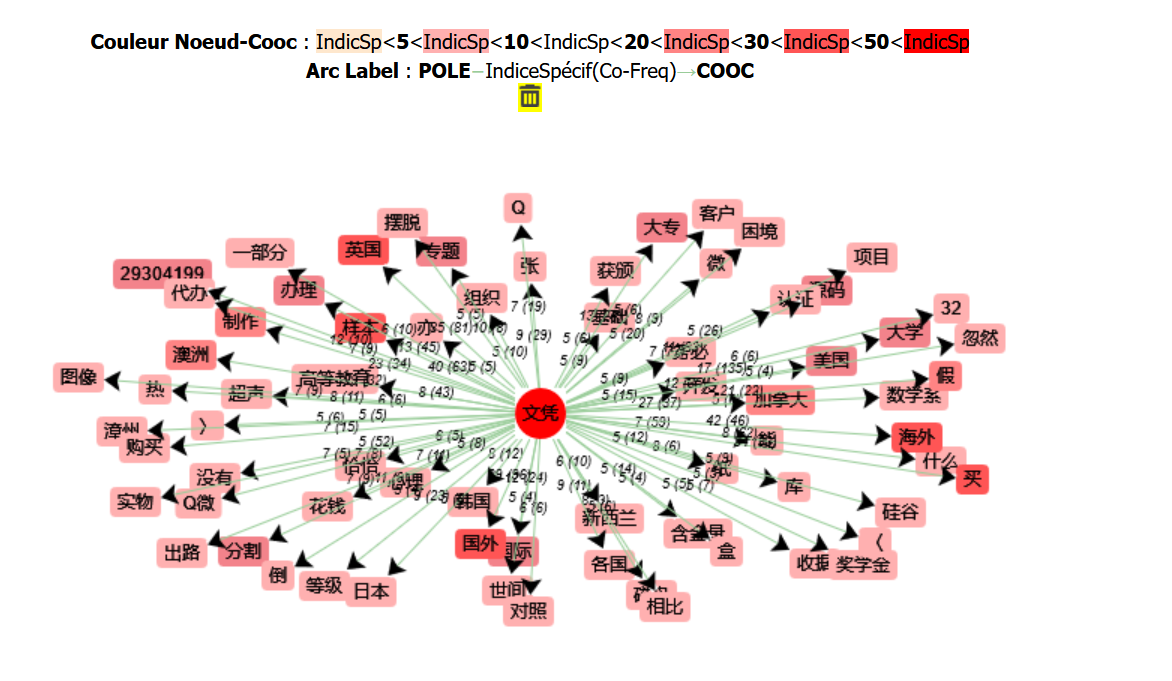
La cooccurrence est la présence simultanée (mais pas forcément contiguë) dans un fragment de texte des occurrences de deux formes données. termes co-fréquents surreprésentés dans les contextes de ce terme. Met en évidence les mots qui se trouvent le plus souvent à côté du pôle (mot recherché). Ici les cooccurents sont classés par ordre de spécificités. Il est frappant de constater que sur les 14 premiers cooccurents du mot : 文凭 wénpíng (diplôme), 6 relèvent du champ lexical de l'étranger. On trouve dans l'ordre : 国外 à l'étranger, 英国 Royaume-Uni, 海外 à l'étranger, 澳洲 Australie, 国际 international, 加拿大 Canada. Même en restant prudent, on pourrait dégager le champ lexical de la fraude : le deuxième cooccurent est le verbe "acheter" 买. On ne peut s'empêcher de penser à la fraude de diplômes, qui est un vrai fait de société en Chine. Le 9ième cooccurent est l'adjectif "faux" 假. On se demande si le verbe "fabriquer" 制作" et le terme "modèle" "样本" respectivement aux 5ème et 6ème rangs, n'entrent dans le même registre.
La préparation des nuages de mots :
Les nuages de mots permettent d’avoir une vue d’ensemble rapide sur la fréquence des mots dans le corpus. Plus un mot est fréquent, plus il sera inscrit en gros sur l’image. Après avoir préparé nos fichiers concaténés, on importe les fichiers dump pour créer les nuages de mots en ligne par wordclouds. Pour mieux adapter les textes chinois et le coréens, on a essayé sur plusieurs sites, comme wordart en cours ou même les sites spécialisés au chinois, enfin, on a fait la sélection entre eux.
Le résultat :
Pour le coréen :
Sur le nuage de mots généré à partir du corpus coréen, nous avons dû faire un tri afin d’obtenir un résultat cohérent. Comme le fichier que nous utilisons est segmenté, les particules sont séparées des mots et deviennent les mots les plus fréquents dans le corpus. Il a donc fallu les supprimer pour faire apparaître les autres mots. On peut ainsi voir que le mot le plus fréquent est notre motif 졸업장 (diplôme), suivi de près par 졸업 (obtention d’un diplôme), 대학 (université), et 고등학교 (lycée). Dans le même registre, peut aussi apercevoir 졸업생 (diplômé), 졸업식 (cérémonie de remise des diplômes), 학생 (élève), et 교육 (éducation), mais aussi 취업 (embaucher), et 제공 (offre), qui penchent plutôt vers le monde du travail. Nous avons également observé d’autres mots un peu moins attendus, comme 미국 (Etats-Unis), 온라인 (en ligne), mais aussi 생각 (pensée), 선택 (choix), 방법 (méthode), 사람 (personne), et 생활 (mode de vie), qui indiquent une certaine remise en question de la part des coréens.

Pour le français :
Nous avons observé que sauf notre motif « diplôme », les mots « formation », « faux », « Verdir », « double diplôme », « métiers » apparaissent le plus fréquemment dans le contexte français. Étant donné que la quasi-totalité de notre corpus provient de forums et de blogs, on peut presque en déduire que ces expressions à haute fréquence reflètent un effet secondaire de l'influence des diplômes sur la société, notamment sur les classes les plus jeunes.

Pour le chinois :
Sur le nuage de mots on retrouve le terme 文凭 wénpíng et en plus grande proportion que le terme 证书 zhèngshū (certificat) ici proche de son déterminant 学位 avec lequel il forme le mot diplôme. Outre nos motifs on retrouve pas mal de mots appartenant au champ lexical de l'administration : 考试 "examen", 学历"niveau d'études", 注册 "inscription", 大学 "université", 学校"école", etc. et des études en général : 学生 "étudiant", 课程 "programme de cours", etc. Ce qui entoure notre motif "diplôme" est ici assez homogène, le thème reste vraiment les études et on ne voit pas les cooccurents que l'on avait avec ITrameur et qui révélaient d'autres champs lexicaux (l'étranger, la fraude).
